
W sztucznej inteligencji (AI) uprzedzenia to osądy lub upodobania, które prowadzą do błędnych decyzji. W niektórych przypadkach te uprzedzenia mogą być pomocne, na przykład gdy pomagają nam w dokonywaniu lepszych prognoz. Jednak w innych przypadkach te uprzedzenia mogą być szkodliwe, prowadząc do nieoptymalnych lub nawet katastrofalnych decyzji.
Istnieje wiele różnych rodzajów uprzedzeń, które mogą wpływać na systemy AI. Niektóre z najczęstszych obejmują:
– Błąd potwierdzenia: Jest to tendencja do poszukiwania informacji, które potwierdzają nasze wcześniejsze przekonania i ignorowania informacji, które są z nimi sprzeczne.
– Błąd selekcji: Jest to tendencja do wybierania próby danych, która nie jest reprezentatywna dla całej populacji.
– Nadmierne dopasowanie: występuje, gdy model jest zbyt ściśle dopasowany do danych uczących i nie daje się dobrze uogólnić na nowe dane.
– Niedopasowanie: występuje, gdy model nie jest wystarczająco złożony, aby uchwycić podstawowe wzorce w danych.
Te uprzedzenia mogą prowadzić do niedokładnych wyników z systemów AI. Na przykład, jeśli model jest szkolony na tendencyjnym zbiorze danych, może nauczyć się utrwalać te uprzedzenia. Może to mieć szkodliwe konsekwencje w świecie rzeczywistym, na przykład gdy systemy rozpoznawania twarzy są szkolone na zbiorach danych, które nie są reprezentatywne dla różnorodności populacji, co prowadzi do błędów w identyfikacji osób kolorowych.
W tym artykule omówimy historię stronniczości w treści generowanej przez sztuczną inteligencję oraz sposoby identyfikowania stronniczości w treści generowanej przez AI.
Historia uprzedzeń w treściach generowanych przez sztuczną inteligencję
Stronniczość w sztucznej inteligencji nie jest nowym zjawiskiem. W rzeczywistości istnieje od wczesnych dni badań nad AI. Jeden z pierwszych odnotowanych przypadków stronniczości w sztucznej inteligencji miał miejsce w 1956 roku, kiedy informatyk Alan Turing zaproponował test mający na celu określenie, czy można powiedzieć, że maszyna wykazuje inteligentne zachowanie.
W swoim artykule „Computing Machinery and Intelligence” Turing zaproponował, że jeśli maszyna może oszukać człowieka, aby myślał, że jest innym człowiekiem przez ponad 30% czasu, to można ją uznać za inteligentną.
Jednak, jak zauważyła badaczka AI, Joy Buolamwini, „test na sztuczną inteligencję jest stronniczy w stosunku do kobiet i osób kolorowych, ponieważ opiera się na zdolności maszyny do oszukania człowieka, aby pomyślał, że jest innym człowiekiem”.
Innymi słowy, test jest skierowany przeciwko grupom osób, które tradycyjnie są niedostatecznie reprezentowane w badaniach i rozwoju AI. Ta tendencja została przeniesiona do innych aspektów badań i rozwoju sztucznej inteligencji, takich jak tworzenie zestawów danych.
Zestawy danych to kolekcje danych, które są używane do uczenia i testowania modeli uczenia maszynowego. Te zbiory danych mogą być obciążone na wiele sposobów, na przykład przez błąd selekcji (obejmujący tylko niektóre rodzaje danych) lub błąd potwierdzenia (obejmujący tylko dane, które potwierdzają istniejące wcześniej przekonanie).
Stronnicze zestawy danych mogą prowadzić do stronniczych modeli uczenia maszynowego. Na przykład, jeśli zestaw danych używany do uczenia systemu rozpoznawania twarzy jest stronniczy, wynikowy system może być niedokładny w swoich przewidywaniach.
Zostało to zademonstrowane w 2016 r., kiedy Zdjęcia Google udostępniły nową funkcję, która automatycznie oznaczała zdjęcia etykietami, takimi jak „pies” lub „kot”. Jednak system oznaczył również czarnego mężczyznę jako „goryla”, co doprowadziło do oskarżeń o rasizm.
Incydent doprowadził Google do zmiany nazw etykiet, a także spowodował, że firma utworzyła wewnętrzny zbiór danych zawierający ponad 100 000 obrazów, których użyła do trenowania swojego systemu, aby był dokładniejszy.
Pomimo tych wysiłków uprzedzenia w treściach generowanych przez sztuczną inteligencję nadal stanowią problem, co widać na poniższym wykresie. W 2017 roku naukowcy z Vanderbilt University odkryli, że trzy komercyjne systemy rozpoznawania twarzy były dokładne przy identyfikacji białych mężczyzn, ale mniej dokładne przy identyfikacji kobiet i osób kolorowych.
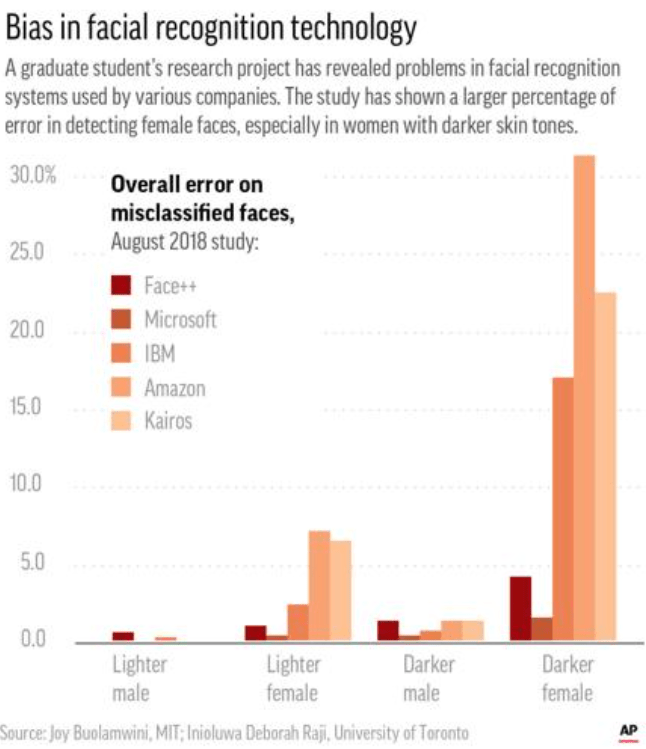
Systemy te częściej błędnie identyfikowały czarne kobiety jako mężczyzn, a także częściej oznaczały zdjęcia białych mężczyzn jako „neutralne” lub „nieznane”.
Naukowcy doszli do wniosku, że „systemy sztucznej inteligencji dostępne obecnie dla ogółu społeczeństwa wykazują znaczne uprzedzenia rasowe i płciowe”.
Sposoby wykrywania uprzedzeń w treściach generowanych przez sztuczną inteligencję
Istnieje wiele sposobów identyfikowania uprzedzeń w treściach generowanych przez sztuczną inteligencję. Jednym ze sposobów jest zbadanie zestawu danych, który został użyty do uczenia modelu uczenia maszynowego.
Jeśli zbiór danych jest stronniczy, prawdopodobne jest, że wynikowy nauczanie maszynowe model będzie również stronniczy. Innym sposobem zidentyfikowania stronniczości jest zbadanie danych wyjściowych modelu uczenia maszynowego.
Jeśli dane wyjściowe są konsekwentnie niedokładne dla pewnych grup ludzi, może to wskazywać na stronniczość. Na koniec ważne jest również rozważenie kontekstu, w którym używany jest model uczenia maszynowego.
Na przykład, jeśli system rozpoznawania twarzy jest używany do celów egzekwowania prawa, jest bardziej prawdopodobne, że będzie miał negatywny wpływ na osoby kolorowe, które już teraz są nieproporcjonalnie często atakowane przez policję.
Istnieje wiele sposobów na ograniczenie uprzedzeń w treściach generowanych przez AI. Jednym ze sposobów jest użycie większego i bardziej zróżnicowanego zestawu danych podczas uczenia modelu uczenia maszynowego.
Innym sposobem na zmniejszenie błędu systematycznego jest zastosowanie techniki zwanej powiększaniem danych, która polega na sztucznym generowaniu dodatkowych punktów danych, które są zróżnicowane pod względem rasy, płci i innych cech.
Na koniec ważne jest również rozważenie wpływu treści generowanych przez sztuczną inteligencję na wrażliwe grupy ludzi przed udostępnieniem systemu światu.
Wniosek
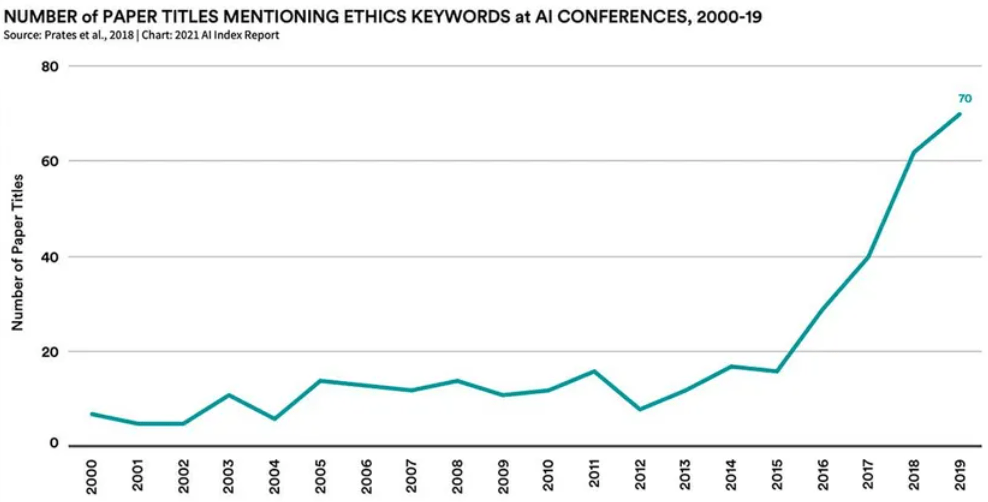
Jak widać na poniższym wykresie, etyka w sztucznej inteligencji stała się gorącym tematem w świecie sztucznej inteligencji. AI może być stronnicza na wiele sposobów, a te uprzedzenia mogą mieć negatywny wpływ na wrażliwe grupy ludzi, takie jak kobiety i osoby kolorowe.
Istnieje wiele sposobów na zmniejszenie stronniczości w treści generowanej przez sztuczną inteligencję, na przykład przy użyciu większego i bardziej zróżnicowanego zestawu danych podczas uczenia modelu uczenia maszynowego. Ważne jest również rozważenie wpływu treści generowanych przez AI na wrażliwe grupy ludzi przed udostępnieniem systemu światu.
Podejmując te kroki, możemy zacząć ograniczać uprzedzenia w treściach generowanych przez sztuczną inteligencję i tworzyć bardziej sprawiedliwą przyszłość dla wszystkich.
Bibliografia