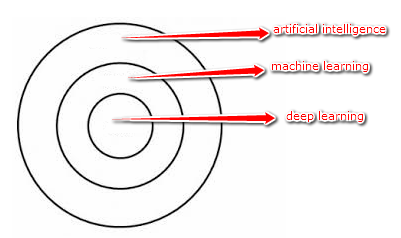
Branża ubezpieczeniowa znajduje się teraz w ekscytującym miejscu, nie tylko z powodu pandemii, ale także z powodu rozwoju technologii także takich jak sztuczna inteligencja. Na świecie zachodzi wiele zmian, zwłaszcza jeśli chodzi o sztuczną...

Jak zmienia się branża ubezpieczeniowa pod wpływem sztucznej inteligencji?
czytaj dalej