Chociaż te trzy terminologie są zwykle używane zamiennie, nie odnoszą się do podobnych zagadnień. Przyjrzyjmy się trzem zakresom i porównajmy sztuczną inteligencję z uczeniem maszynowym z niewielkim ujęciem głębokiego uczenia się.
Czy zatem istnieje różnica między sztuczną inteligencją a uczeniem maszynowym i uczeniem głębokim?
Oto diagram, który próbuje zwizualizować relacje między nimi i ich wzajemne relacje:
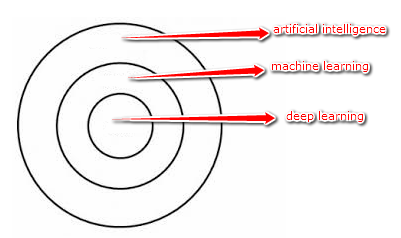
Rysunek 1: Sztuczna inteligencja a uczenie maszynowe i uczenie głębokie
Jak widać powyżej trzech koncentrycznych okręgów, uczenie głębokie (Deep Learning) to podzbiór uczenia maszynowego (Machine Learning), który jest dodatkowo podzbiorem sztucznej inteligencji (Artificial Intelligence).
Tak więc sztuczna inteligencja jest wszechogarniającą ideą, która pojawiła się na początku , a następnie rozwinęła się z pomocą uczenia maszynowego. Ostatecznie rozwinęło się i wciąż się rozwija głębokie uczenie, które obiecuje przyspieszyć postęp sztucznej inteligencji.
Poszukajmy dalej, abyś mógł rozpoznać, różnice i zastosowania AI, ML lub DL.
Co to jest sztuczna inteligencja (AI)?
Jak sugeruje tytuł, sztuczną inteligencję można luźno interpretować jako integrację ludzkiego mózgu z maszynami. Sztuczna inteligencja to konstelacja kilku różnych technologii, które umożliwiają maszynom rozumienie, działanie i samo-uczenie się. Z tego powodu wszyscy mają inną definicję sztucznej inteligencji.
Trochę komplikując sprawę, muszę wspomnieć, że sztuczną inteligencję można podzielić na dwie grupy.
Wąska AI
Większość tego, czego używamy w naszym codziennym życiu, to wąska sztuczna inteligencja, która wykonuje pojedyncze zadanie lub zbiór powiązanych zadań.
Oto kilka przykładów:
Cyfrowi asystenci, tacy jak Siri, którzy mogą zamówić pizzę lub kawę
- Oprogramowanie, które bada dane w celu optymalizacji danego procesu biznesowego, na przykład systemy zarządzania churnem (odejścia klientów), które próbują manipulować ceną, aby klient nie przeniósł się do konkurencji.
Takie systemy są solidne, ale pole do popisu jest wąskie: zwykle koncentrują się na osiągach konkretnego procesu lub zadania. Jednak wąska sztuczna inteligencja ma ogromną moc transformacji przy odpowiednim zastosowaniu i nadal zmienia najskuteczniej sposób, w jaki pracujemy i żyjemy.
Ogólne AI
Sztuczna inteligencja ogólna (AGI) byłaby inteligencją maszyny zdolnej do zrozumienia świata i każdego człowieka oraz posiadającej nieograniczony potencjał uczenia się, jaki i wykonywania ogromnego zakresu zadań z niezwykle wysoką wydajnością. AGI nie istnieje i pojawia się w opowiadaniach science-fiction od ponad wieku, ale badacze i firmy twierdzą, że możliwe jest szybkie zbudowanie takiej technologii.
GOF AI
Sztuczna inteligencja to szersze myślenie, które obejmuje wszystko, od dobrej staromodnej sztucznej inteligencji (GOFAI) po futurystyczne nauki stosowane, takie jak głębokie uczenie się. Czy pamiętasz Blue Chip zdolny do gry w szachy (grający z mistrzami szachownicy)? To nie była sztuczna inteligencja i uczenie maszynowe, ani uczenie się przez wzmacnianie (reinforcement learning). To było podejście / nauka metodą brutalnego wykorzystania siły algorytmów. To była dobra, staroświecka sztuczna inteligencja (ai) z angielskiego (Good Old Fashioned AI).
Co to jest uczenie maszynowe (komputerowe) (ML)?
Uczenie maszynowe (ML) ma na celu umożliwienie maszynom prowadzenia badań z wykorzystaniem dostarczonych rekordów i dokonywania poprawnych prognoz. Część edukacyjna jest tutaj niezbędna. Uczenie maszynowe jest podzbiorem AI (jak wykazałem powyżej).
Uczenie maszynowe polega na przekazywaniu danych algorytmowi i umożliwieniu mu badania dzięki udostępnionym danym. To proces uczenia się prowadzony przez algorytm.
Wyobraź sobie sklep ze skanerami wykorzystującymi sztuczną inteligencję i uczenie maszynowe, które identyfikują rodzaj owocu na podstawie jego atrybutów:
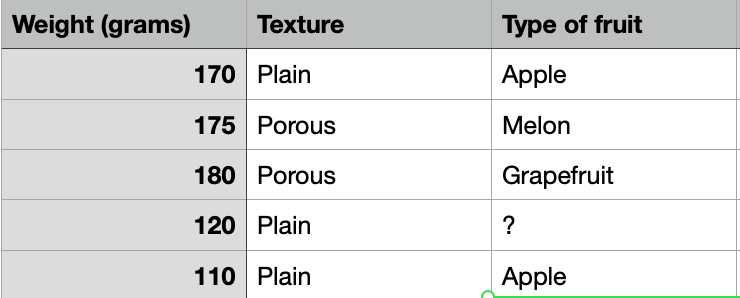
Jednak jeden z wierszy podaje wyłącznie wagę i teksturę i nie ma danych o rodzaju owoców. Nawiasem mówiąc, naukowcy zajmujący się danymi są tutaj bardzo ważni przy projektowaniu takich tabel. Niewłaściwa struktura może wprowadzić w błąd operacje biznesowe. ML nie wyjdzie poza strukturę. Nie zaproponuje, mówiąc prościej, innej tabeli. Będzie się poruszał w jej obrębie.
Sztuczną inteligencję i uczenie maszynowe można użyć do „odgadywania”, czy owoc jest pomarańczą czy jabłkiem. To uczenie się na podstawie danych i podejmowanie decyzji.
Po wprowadzeniu danych algorytm zbada różne cechy pomarańczy i jabłka. Algorytm może się uczyć automatycznie, ale byłby to tylko algorytm. Uczenie maszynowe jest inne. Może podejmować decyzje. Uczenie się, pozwala na podejmowanie coraz to lepszych decyzji.
Systemy oparte na uczeniu maszynowym (podzbiór AI), które uczą się na podstawie danych, będą w stanie zapełnić tysiące wierszy (wykonując miliony zadań) w mgnieniu oka. To najbardziej ekscytująca część nauki – automatyzacja, możliwa dzięki rozpoznawaniu wzorców i informatyce.
Systemy AI i ML mogą zapewnić szybkie odpowiedzi, co oznacza, że różnicę między owocami można bardzo szybko uchwycić. Im więcej zadań jest wykonywanych, tym więcej wiedzy gromadzi sztuczna inteligencja.
Z tego powodu duże zbiory danych mają kluczowe znaczenie dla technologii AI i ML. Algorytm uczenia maszynowego może uczyć się bardzo szybko, a rozmiar stosu danych nie ma znaczenia. W naszym przykładzie im więcej owoców zostanie zeskanowanych przez skaner, tym lepszy będzie proces decyzyjny programu komputerowego.
Aby rozwiązać zagadkę, kluczowe jest posiadanie inteligentnych naukowców zajmujących się danymi i inteligentnego programowania. Mówiąc smart, mam na myśli ludzi, którzy rozumieją znaczenie celu biznesowego systemów AI.
Klasyfikacja sztucznej inteligencji i algorytmów uczenia maszynowego
Algorytmy uczenia maszynowego są skatalogowane w:
- uczenie nadzorowane (dane treningowe są oznaczane odpowiedziami, informacje są dobrze oznaczone)
- uczenie się bez nadzoru (wszelkie oznaczenia i odpowiedzi, które mogą istnieć, nie są dostępne dla algorytmu).
Uczenie nadzorowane dzieli się na:
- klasyfikację (przewidywanie wyników nienumerycznych, np. program może oszacować prawdopodobieństwo zamknięcia konta bankowego przez klienta i przejścia do konkurencji)
- regresję (przewidywanie odpowiedzi liczbowych, takich jak zakres zmian cen w wyniku warunków pogodowych).
Uczenie się bez nadzoru:
- grupowanie (wyszukiwanie skupień danych o porównywalnych obiektach, takich jak pula klientów kupujących codziennie określone produkty, klienci narzekający na tę samą cechę, klastry klientów kupujące podobne produkty),
- przynależność (znajdowanie częstych sekwencji obiektów, powiedzmy, że aplikacja może dowiedzieć się, że zwykle bierzesz UBER i zatrzymujesz się po drodze na Starbucks)
- dimensionality discount (prognozowanie, zbieranie charakterystyk i ekstrakcja funkcji)
Zastosowania uczenia maszynowego (ML)
Myślę, że to właściwy moment, aby wspomnieć, że ludzka inteligencja wiąże się z adaptacyjnym uczeniem się i doświadczeniem. Nie zawsze zależy to od danych dostarczonych wcześniej, takich jak te wymagane w przypadku uczenia maszynowego. Moim zdaniem sztuczna inteligencja i uczenie maszynowe zawsze będą współistnieć z ludźmi. Inteligencja ludzka jest w stanie wymyślić fantastyczny sprzęt i oprogramowanie, które następnie tworzą system komputerowy lub złożone systemy. Jeśli spojrzysz na poniższe przykłady z tej perspektywy, staje się oczywiste, że uczenie maszynowe i sztuczna inteligencja wspierają ludzkie zachowanie, pozwalając nam zwiększyć wydajność i produktywność.
Dane pochodzące z rozpoznawania obrazu
Dobrze znanym i typowym przykładem uczenia maszynowego w świecie rzeczywistym jest rozpoznawanie obrazów.
Przykłady rozpoznawania obrazów ze świata rzeczywistego:
- Oznacz prześwietlenie ciała jako rakowe lub nie. Analiza danych przeprowadzona przez uczenie maszynowe AI może pomóc lekarzom, badaczom i naukowcom szybko zidentyfikować, czy dane zdjęcie rentgenowskie zawiera zmiany nowotworowe. Nawet nie wspominając, że to samo można zrobić, wyodrębniając obrazy z wideo. Jeśli lekarz przeprowadzi endoskopię i nagra wideo, program oparty na uczeniu maszynowym może zamienić wideo na zbiór obrazów i oznaczyć obiekty (podjąć decyzję).
- Przypisz imię do przedstawionej twarzy – jeśli posiadasz smartfon, możesz skatalogować swoje rodzinne zdjęcia. Uczenie maszynowe może rozpoznać twarz konkretnej osoby i „umożliwić” jej wyszukiwanie.
- Rozpoznawanie pisma ręcznego na tablecie. Jesteś osobą mówiącą i piszącą po rosyjsku, a może umiesz pisać po rosyjsku, polsku i angielsku? Uczenie maszynowe może zrozumieć Twój styl pisania, a przetwarzanie języka naturalnego (NLP) będzie w stanie wyodrębnić odpowiednie dane i przetłumaczyć je na znaki. Superinteligencja? Nie, to tylko umiejętność konsumowania dużej ilości danych (miliony przykładów pisma ręcznego) i uczenia się rozpoznawania, która prowadzi do decyzji podejmowanych przez algorytmy.
Rozpoznawanie mowy
Sztuczna inteligencja może swobodnie zamieniać słowa w tekst. Program komputerowy może przekształcić mowę (kolejny wielki nośnik danych) i głos przechwycony na żywo w pliki tekstowe. Intensywność w pasmach czasowo-częstotliwościowych może również segmentować głos.
Przykłady rozumienia mowy wspomaganego sztuczną inteligencją:
- Poszukiwanie dźwięków (na przykład nagrany dźwięk ptaka może pomóc w rozpoznaniu gatunku)
- Kontrola sprzętu – „Tesla, odbierz mnie z domu” i samochód zaczyna zbliżać się do miejsca zamieszkania.
- Aplikacje takie jak Google Home czy Amazon Alexa należą do szeroko rozpowszechnionych zastosowań sztucznej inteligencji.
Opieka zdrowotna
Uczenie maszynowe może pomóc w diagnozowaniu chorób. Wielu lekarzy używa chatbotów (to rozmowa z drugą stroną poprzez czat internetowy) do rozpoznawania mowy do identyfikowania wzorców objawów lub rozpoznawania obrazów w celu wykrycia COVID.
Przykłady rzeczywistej diagnostyki medycznej i podejścia do problemów:
- Pomoc w przygotowaniu diagnozy lub zaproponowaniu planu leczenia (przykład: pacjent jest przesłuchiwany przez program komputerowy i proszony o wgranie zdjęć i opisów lekarskich).
- Analiza płynów ustrojowych w celu rozpoznania choroby.
- W rzadkich chorobach połączenie oprogramowania do rozpoznawania twarzy i uczenia maszynowego pomaga zidentyfikować skany ciała pacjentów i rozpoznać fenotypy powiązane z rzadkimi zaburzeniami genetycznymi.
Analizy predykcyjne
Uczenie maszynowe może podzielić dostępne dane na grupy. Następnie analitycy zmierzą prawdopodobieństwo błędu po zakończeniu klasyfikacji.
Przykłady analizy predykcyjnej:
- Przewidywanie, czy transakcja jest oszustwem, ile transakcji w roku będzie próbami wyłudzenia. Technologie sztucznej inteligencji mogą rozpoznawać ton, głos i uczucia oraz oznaczać zlecenia telefoniczne jako próby dokonywania fałszywych transakcji.
- Opracowanie systemów prognozowania w celu ilościowego określenia prawdopodobieństwa błędu, na przykład tego, ile przesyłek trafi kurierskich do złej lokalizacji.
Ekstrakcja
Z nieustrukturyzowanych danych uczenie maszynowe może wyodrębnić ustrukturyzowane informacje.
Przykłady aplikacji:
- Opracowywanie strategii zapobiegania, diagnozowania i leczenia zaburzeń.
- Zbieranie danych maratończyków i wyszukiwanie wzorców, które można następnie wykorzystać w obiektach treningowych, projektowaniu sprzętu sportowego (np. obuwia).
Procedury te są zwykle powtarzalne, ale uczenie maszynowe może dekodować ogromną ilość danych i sprawdzać wzorce, które następnie nauka lub biznes może wykorzystać do określonych ulepszeń.
Co to jest uczenie głębokie (DL)?
Jak wspomniałem, głębokie uczenie jest podzbiorem uczenia maszynowego; jest to podejście do realizacji uczenia maszynowego. Innymi słowy, głębokie uczenie się to kolejna ewolucja uczenia maszynowego.
Algorytmy uczenia głębokiego są z grubsza stymulowane przez wzorce odkryte w ludzkim mózgu. Tak jak używamy naszych mózgów do znajdowania wzorców i klasyfikowania kilku rodzajów informacji, algorytmy głębokiego uczenia się można nauczyć, aby wykonywały identyczne zadania.
Nasz mózg przechowuje nieustrukturyzowane dane i wciąż podchodzi do ogromnych problemów. Sztuczne sieci neuronowe (SSN) to algorytmy, które zamierzają naśladować sposób, w jaki nasz mózg podejmuje decyzje.
Głębokie uczenie może rutynowo znaleźć punkty, które należy wykorzystać do klasyfikacji.
Różnice pomiędzy uczeniem maszynowym (ML) a uczeniem głębokim (DL), można by ująć mniej więcej tak:
ML:
- Wymaga małej ilości danych wejściowych, aby móc rozpocząć uczenie i podejmować coraz to lepsze decyzje.
- W większości przypadków, ML nadaje się do rozwiązywania konkretnego, dobrze opisanego problemu.
- Skomplikowane wyzwania, ktoś (np. naukowiec) musi zamienić na mniejsze, bardziej precyzyjne. ML będzie rozwiązywał te mniejsze, aby w efekcie pomóc rozwiązać to duże, skomplikowane wyzwanie.
- Wynik dostarczony przez uczenie maszynowe jest łatwy do wyjaśnienia, gdyż zasady rozwiązywania są jasne i strukturalizowane.
- Dane historyczne pozwalają maszynie na podejmowanie decyzji.
DL:
- Wymaga bardzo, ale to bardzo dużej ilości danych wejściowych.
- Algorytmy same wyszukują wzorce w danych.
- Nie tyle szuka się rozwiązania problemu, co wzorców w dostarczonych danych.
- Wyjaśnienie efektów może być bardzo trudne, gdyż to algorytm sam buduje wzorce na bazie których dostarczane są rekomendacje (efekt czarnej skrzynki).
- Dane służą poszukiwaniu wzorców, a nie poszukiwaniu decyzji. Dlatego też dane historyczne nie są tak ważne, jak „jakiekolwiek” dane w dużych ilościach.
Zastosowania uczenia głębokiego.
- Zautomatyzowana jazda – zespoły zajmujące się nauką o samochodach wykorzystują wiedzę głębokiego uczenia się, aby dostrzegać obiekty, takie jak znaki, sygnalizacja świetlna, zwierzęta itp.
- Sieć neuronowa w lotnictwie i obronie – uczenie głębokie służy do rozpoznawania obiektów z satelitów, które wykrywają obszary zainteresowania (na przykład jeziora, lasy, zwierzęta).
- Badania medyczne – Badacze nowotworów używają systemów komputerowych opartych na głębokim uczeniu się, aby automatycznie odkrywać komórki rakowe. Na Uniwersytecie Kalifornijskim w Los Angeles zespoły analityków danych skonstruowały specjalny mikroskop, który dostarcza wielowymiarowych statystyk, które umożliwiają trenowanie oprogramowania do głębokiego uczenia się w celu dokładnego wykrywania większości komórek nowotworowych.
- Automatyka przemysłowa – DL pomaga czuwać nad bezpieczeństwem pracowników w zasięgu ciężkiego sprzętu. Oprogramowanie może rutynowo wykrywać, kiedy ludzie lub przedmioty znajdują się w niebezpiecznej odległości od maszyn. W połączeniu z uczeniem maszynowym może zbudować podsumowanie miejsc, których ludzie powinni unikać.
- Elektronika – uczenie głębokie jest używane w słuchaniu i tłumaczeniu mowy. Na przykład system sztucznej inteligencji pomaga gadżetom odpowiadać na Twój głos i poznawać Twoje preferencje. Sieci neuronowe mogą rozpoznawać dialekty i dostosowywać prędkość rozpoznawania mowy do regionów geograficznych.
Podsumowanie
Jak widać, istnieje znacząca różnica i krystalicznie wyraźny związek między sztuczną inteligencją (AI), uczeniem maszynowym (ML) a głębokim uczeniem (DL).
Kiedy powinniśmy używać sieci neuronowej? To zależy. Kiedy algorytm uczenia maszynowego jest odpowiedni? To zależy.
Sztuczna inteligencja i uczenie maszynowe oferują ogromną różnorodność korzyści, ale dzięki nauce stratedzy muszą rozpoznać, które podejście najlepiej służy biznesowi. Maszyny, sieci i nauka o danych tworzą super wydajną kombinację, która ostatecznie musi służyć biznesowi.
Zrozumienie różnicy między sztuczną inteligencją a uczeniem maszynowym i uczeniem głębokim pomaga podejmować lepsze decyzje. Każda pula algorytmów daje inne wyniki i wymaga różnych typów, rozmiarów i jakości wprowadzanych danych.
Zapisz się do newslettera jeśli masz ochotę i otrzymuj teksty na maila.